.png)
Last week we made the news with our research on how we used LLMs to find vulnerabilities in a dozen open source applications used by the Dutch government. Our analysis surfaced hundreds of issues in a matter of hours, including an unauthenticated LFI that led to an RCE on the Azure environment. The single most important detail of that run wasn't the severity. It was the bill of materials: a commodity language model, a handful of instructions, and a harness that knew what to do with both.
That demonstration was the visible result. Apart from these Government repositories, we’ve been able to find critical vulnerabilities (some of them already disclosed, most of them not since a patch has not been deployed yet) in large open source projects. Today we're publishing the methodology behind it, and open sourcing the tool that allows you to do the same thing. There will be some differences between this setup and our own internal one, predominantly because we chose to adjust the setup for OpenHack so it can run inside your coding Harness, which makes it significantly easier to use.
OpenHack is now available under the MIT license. It's a file-based workspace and a set of agents that mirror how our internal research team performs automated OpenHack vulnerability discovery on open source software. It is adapted to run inside the model harnesses you probably already have on your laptop: Claude Code, Codex, Cursor, or anything else that gives an LLM terminal and filesystem access.
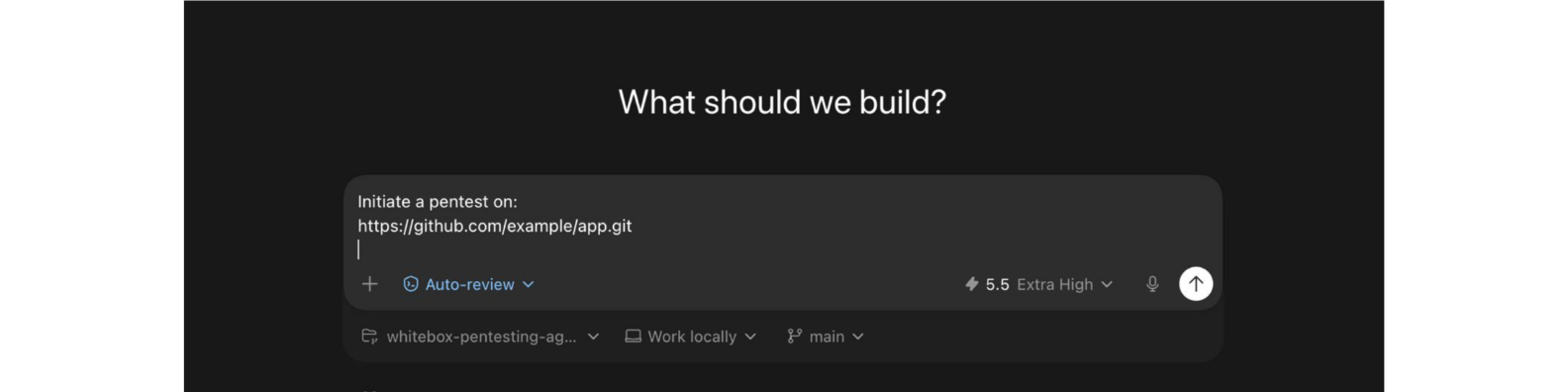
Scenario-Based Workflow for Precision Vulnerability Discovery
The temptation when you give a strong LLM a codebase is to let it improvise. "Read this repo and tell me what's vulnerable." It will produce something. The output will be a mixture of plausible bugs, hallucinated bugs, real bugs explained wrongly, and the occasional sharp insight. Triage takes longer than just reading the code yourself.
We've found two failure modes drive most of that noise:
- Unscoped prompts. The agent doesn't know what question it's answering, so it answers all of them at low confidence.
- Self-graded findings. The same agent that proposed the bug decides whether the bug is real. There's no independent check.
The workflow of OpenHack is designed around fixing those two things. Reviews are scenario-first: every unit of agent work is exactly one routing unit, one expert, and one proof question. And the agent that proposes a finding is not the agent that admits it.
This rigorous, multi-stage process is what enables us to move beyond low-confidence bugs to find critical, escalatable issues, like the unauthenticated LFI that led to an RCE mentioned earlier. This reinforces the value of the Scenario-Based Workflow over "improvisation."
The durable chain looks like this:
- RECON ITEM
ROUTING UNITSCENARIOSCENARIO RESULT- FINDING CANDIDATE
- TRIAGE DECISION
- FINDING
A few definitions, because the vocabulary matters:
.png)
The reason for separating "candidate" from "finding" is the same reason a research team has reviewers: the person who wrote the proof shouldn't be the only person deciding it's a proof. The workflow enforces that — finding-triage runs as a different agent, with a different prompt, against the same evidence the expert recorded. Accepted and downgraded triage decisions materialize Markdown reports under findings/.
Hacking without frontier models
We've been saying for a while that AI-assisted vulnerability discovery is about to stop being a research curiosity and start being a commodity capability. The Dutch government study made that concrete. We didn't need a frontier-only system to find the P1 at Open Regels; cheaper models found their way to it too, at a few cents per run. Whatever advantage defenders had in 2024 from "attackers don't have access to good code-understanding tools" is gone in 2026.
The question for the next twelve months isn't whether attackers will industrialize this. The question is whether everyone else can keep up. We'd rather hand programmers the same scaffolding we use internally than watch them re-derive it badly under pressure.
What is OpenHack
OpenHack is a lightweight workspace for source-guided OpenHack security review. It's deliberately not a runtime; it doesn't ship its own model or its own orchestrator. The harness — Claude Code, Codex, Cursor, or a custom runner — provides model execution, terminal access, repository access, and human approval prompts. The workspace provides a durable workflow that produces detailed whitebox pentesting review artifacts.
What that means in practice: every run lives under runs/<target>/<run-id>/, and every important step writes a plain file. Cloned source, recon output, routing units, scenario prompts, scenario results, finding candidates, triage decisions, findings, logs. Open the directory and you can reconstruct exactly what an agent did, what evidence it used, and what a human approved. Re-run a phase and you get the same files. Hand a run off to a colleague and they pick up from OpenHack summarize-run.
The whole CLI fits on one page:
# Create a run from a fresh git checkout
OpenHack init-run demo https://github.com/example/app.git --run-id demo-001
# Choose expert scope, then run reconnaissance
OpenHack run-recon demo demo-001 --all-agents
# Or scope the run to selected experts
OpenHack run-recon demo demo-001 \
--expert injection \
--expert broken-access-control
# Optional: enrich recon with bundled Semgrep rules
OpenHack run-recon demo demo-001 --all-agents --semgrep
# Build the scenario-router prompt from routing units
OpenHack create-scenarios demo demo-001
# Record the router agent's selected backlog
OpenHack record-scenario-backlog demo demo-001 router-result.json
# Render a scenario prompt for an expert agent
OpenHack render-scenario-prompt demo demo-001 S001
# Record an expert's verified result (materializes finding-candidates/)
OpenHack record-scenario-result demo demo-001 S001 result.json
# Render and record independent triage before final findings are created
OpenHack render-finding-triage-prompt demo demo-001 S001-F001
OpenHack record-finding-triage demo demo-001 S001-F001 triage-result.json
# Resume or hand off: prints current counts + next checkpoint
OpenHack summarize-run demo demo-001
If you'd rather not type any of that, open the repo in a coding harness and ask it:
Initiate an OpenHack pentest on https://github.com/example/app.git
The harness reads AGENTS.md, initializes the run, summarizes each checkpoint, and asks you to approve every phase transition. That's the intended workflow for most users.
How a run unfolds
The lifecycle of a review begins with init-run. This initializes a durable, file-based workspace under runs/<target>/<run-id>/, clones the target into sourcecode/, and pins the source commit. By materializing the initial run-config.yaml, we ensure the run is resumable: every subsequent phase leaves behind artifacts that can be inspected or hand-validated at any point.
Phase 1 — Recon. The run-recon command crawls the source to generate recon-items.jsonl alongside specialized inventories covering routes, sinks, exposures, and request boundaries. This culminates in routing-units.jsonl, the fundamental map of the attack surface.
These routing units act as the bridge between raw discovery and expert review. We cluster noisy line-level hits into deterministic review surfaces: auth flows, parsers, and storage boundaries. By presenting the router with hundreds of logical surfaces instead of tens of thousands of raw grep hits, we dramatically increase the precision of the downstream experts.
Expert scope is defined upfront in run-config.yaml. Whether you limit coverage with --expert flags or use --all-agents, the choice is durable. Later phases validate against this configuration to ensure that backlog generation never drifts outside the approved security scope.
An optional --semgrep pass can enrich this recon. We normalize raw results into the standard workspace schema, treating them as high-signal routing evidence rather than verified vulnerabilities. The goal is to point the agent at interesting code, not to skip the verification step.
Phase 2 — Routing. The create-scenarios command prepares the router prompt but does not yet materialize work. The router agent evaluates the attack surface to propose specific pairings of routing units and experts, delivered as structured JSON coverage decisions.
The router’s mandate is to identify where a proof attempt is warranted. A scenario is a single unit of work: one surface, one expert, and one specific proof obligation. If a route touches both access control and injection, the system fans this out into separate scenarios to ensure each expert remains focused on its specific security invariant.
Before files appear in scenarios/backlog/, record-scenario-backlog enforces strict validation. Every high-signal routing unit must be accounted for—either by an active scenario or an explicit coverage decision. If a requirement silently disappears, the recording fails, preventing gaps in the audit trail.
Phase 3 — Expert Review. Each backlog item is rendered into a discrete prompt. An expert agent reviews the target source code against that specific scenario and records its findings via record-scenario-result. This ensures the model is never asked to improvise across an unscoped repo.
Results are categorized as verified, candidate, rejected, or needing more context. When an expert identifies a bug, it materializes a finding-candidate. This is a proposal backed by evidence, but critically, it is not yet a final finding.
While the harness can package these results for convenience, we never perform batch analysis. Every scenario demands its own independent proof, source review, and recorded artifact. This prevents the "hallucination soup" common in unscoped LLM runs.
Phase 4 — Triage. Every candidate is subjected to independent review. A dedicated triage agent evaluates the evidence for reportability, exploitability, and blast radius. It checks the expert's work for confidence and severity before any finding is admitted to the final report.
Only accepted decisions result in Markdown reports under findings/. Rejected candidates remain in the finding-triage/decisions/ audit trail. This allows a human to see not just what was found, but exactly why certain leads were ruled out, maintaining a complete record of the review's reasoning.
Phase 5 — Validation. Finally, validate-run verifies the durable chain of custody. It ensures every final finding can be traced back through its triage decision, candidate proposal, scenario result, and original routing unit.
recon item → routing unit → scenario → scenario result → finding candidate → triage decision → finding
Approvals happen at the scheduling level, not the keystroke level. An operator can approve continuous execution of the backlog, but the structural integrity remains: each scenario gets its own expert review and each candidate gets its own triage decision. There is no shortcut that turns a stack of unreviewed evidence into a final finding without independent verification.
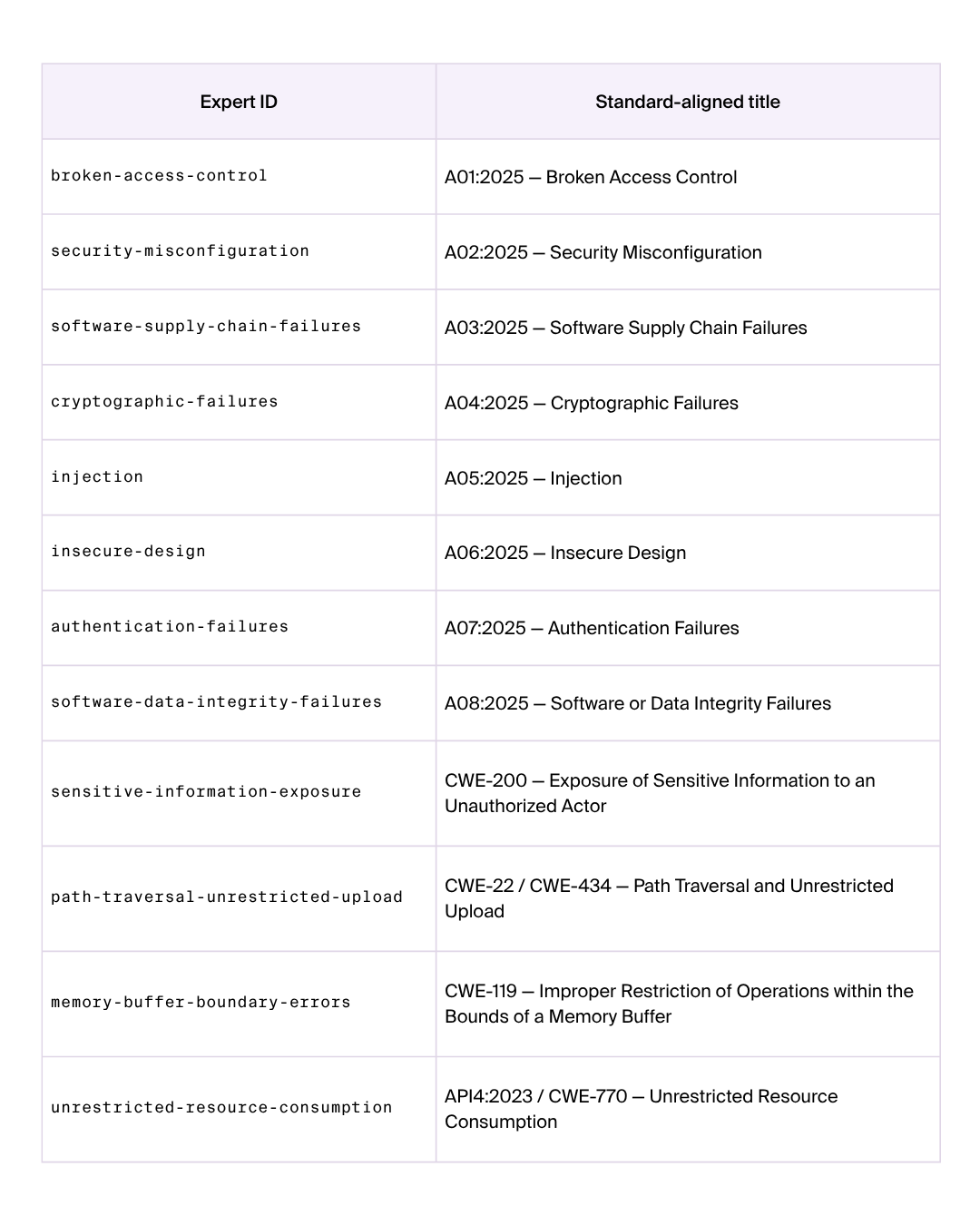
The rest follow the OWASP 2025 numbering. We chose Markdown manifests over Python plugins on purpose: the bar for adding or sharpening an expert should be writing prose about evidence requirements, not learning our class hierarchy. If you want to add a custom expert family — domain-specific issues in fintech protocols, say, or telco signaling — copy a manifest, edit the routing signals and evidence requirements, and add the id to the registry.
The rest follow the OWASP 2025 numbering. We chose Markdown manifests over Python plugins on purpose: the bar for adding or sharpening an expert should be writing prose about evidence requirements, not learning our class hierarchy. If you want to add a custom expert family — domain-specific issues in fintech protocols, say, or telco signaling — copy a manifest, edit the routing signals and evidence requirements, and add the id to the registry.
What's next
We'll keep adding expert families as we sharpen them internally — currently in the pipeline are a few infrastructure-as-code families and a richer set of evidence templates for cryptographic misuse. We'd also like to see the harness integrations grow; right now Claude Code, Codex, and Cursor are the smoothest, but anything that can read AGENTS.md and follow checkpoints can drive a run.
A note on responsible release
We thought hard about whether to publish this. The honest answer is that everything in the repository is methodology, not weaponry. The agents are scoped, the workflow demands human approval, and none of the expert manifests describe novel attack techniques you couldn't find in OWASP, MITRE, or any decent security textbook. What's novel here is the workflow that turns commodity model capability into reproducible review.
Attackers have this workflow already, in one form or another. Releasing it gives defenders a fighting chance to run the same kind of review against their own code before someone else does.
Ready to use the AI workflow?
Repository: github.com/hadriansecurity/OpenHack
License: MIT
Requirements: Python 3.9+
Disclosures: see SECURITY.md in the repository.